
Additional Microservices and Container Security Guidelines
(Back)
The following section provides additional guidelines to securing your microservices and containers.
There is already several guidance documents on secure application development, secure coding practices, and secure deployment practices. This document will focus on the specific security considerations for microservices and containers.
5.1 Securing Platform
Multi-Tenancy
Multi-tenancy within a single Kubernetes cluster is one of the key drivers for digging into the security implications of different deployment patterns. The most secure approach is to only deploy a single application per K8s cluster, but this becomes very inefficient in terms of resource usage and operational maintenance of the utilized infrastructure.
Throughout the following sections, we will illustrate different options for isolating and separating workloads, as well as best practices when establishing your application architecture.
To get started, it is worth briefly covering the difference between a container runtime and traditional VM based workload isolation.
Workload Isolation
The following table lists the different considerations when it comes to workload isolation in containers and VMs.
| Consideration | Description |
|---|---|
| Hard Isolation | Traditional VMs offer strong, "hard" isolation due to their separate kernels. |
| Soft Isolation | Containers provide "soft" isolation using mechanisms like Kubernetes namespaces. |
The most fundamental difference between containers and virtual machines (VMs) is related to the host, or kernel environment in which they run. Each VM runs its own guest OS and as such, has its own kernel. In contrast, a container shares the underlying operating system's kernel with all of the other containers on that host.
As a simple illustration, the following diagram shows the components of an application as it relates to either VMs or containers.
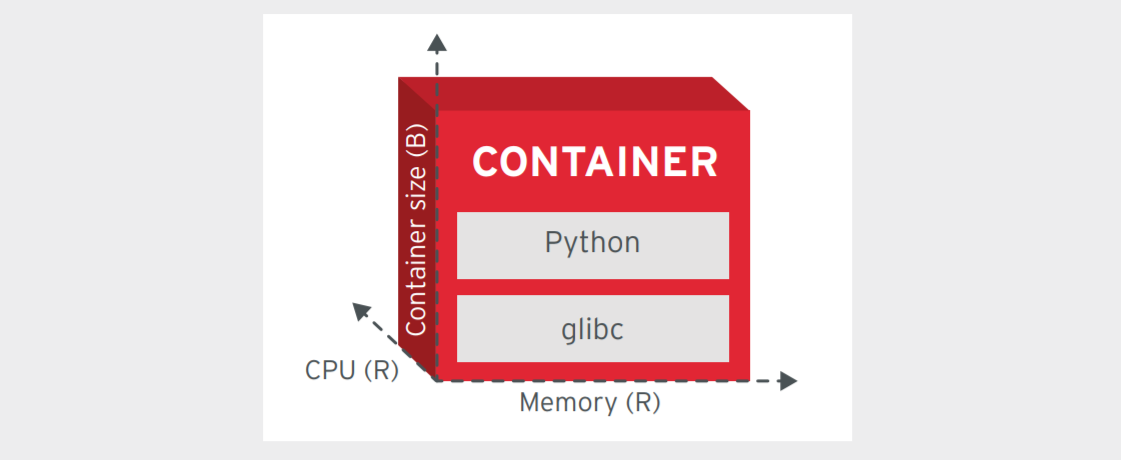 Figure 5-1 - VMs vs Containers
Figure 5-1 - VMs vs Containers
Hard Isolation
Key points to consider when it comes to hard isolation:
| Consideration | Description |
|---|---|
| Strong Isolation | VMs provide strong isolation by running separate guest OS and kernels, offering well-understood security realms. |
| Resource Sharing | Containers share the host OS kernel, enabling faster startup, lower memory footprint, and efficient resource usage. |
Soft Isolation
Key points to consider when it comes to soft isolation:
| Consideration | Description |
|---|---|
| Namespace |
|
| Isolation |
|
Attack Surface
The attack surface of a container is the sum of all the different points where an attacker could potentially exploit the container. The attack surface includes the container image, the container runtime, the host OS, the container network, and the Kubernetes API server.
Consider security implications of:
| Consideration | Description |
|---|---|
| Kubernetes Platform Architecture | nodes, kubelet service, API service, etcd service, control plane. |
| Workload Organization | Pods, containers, namespaces. |
| Ecosystem Services | ingress, storage, certificate management, service mesh. |
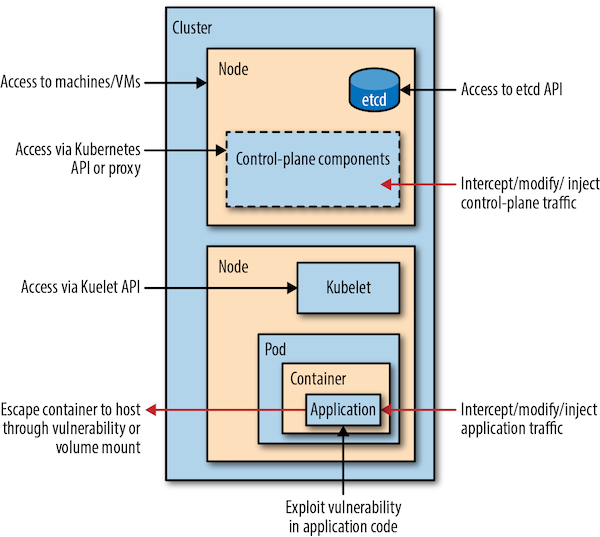 Figure 5-2 - Kubernetes Attack Surface
Figure 5-2 - Kubernetes Attack Surface
Workload Scheduling & Placement
Containers can have dependencies among themselves, dependencies to nodes, and resource demands, that can also change over time. The resources available on a cluster also vary over time, through shrinking or extending the cluster, or by having it consumed by already placed containers. The way we place containers impacts the availability, performance, and capacity of the distributed systems as well. This section covers the scheduling considerations when a workload is scheduled on a node and how Kubernetes manage it.
The following table is a list of considerations when it comes to workload scheduling and placement in Kubernetes.
| Consideration | Description |
|---|---|
| Taints and Tolerations |
|
| Pod Affinity/Anti-Affinity |
|
| Node Affinity/Anti-Affinity |
|
| Built-in vs Custom |
|
Role-Based Access Control (RBAC)
Kubernetes Cluster Authorization
Access controls are implemented on the Kubernetes API layer (kube-apiserver). When an API request comes in, the authorization permissions will be checked to see whether the user has access to be able to execute this command.
| Consideration | Description |
|---|---|
| Role-Based Access Control (RBAC) |
|
| Roles and Binding |
|
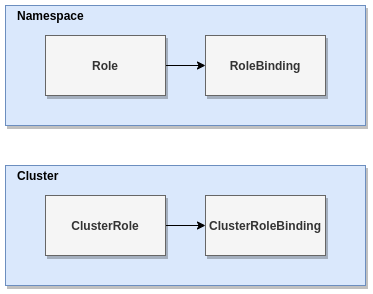 Figure 5-3 - RBAC in Kubernetes
Figure 5-3 - RBAC in Kubernetes
Service Mesh
A service mesh is a programmable framework that allows you to observe, secure, and connect microservices. It doesn't establish connectivity between microservices, but instead has policies and controls that are applied on top of an existing network to govern how microservices interact. Generally a service mesh is agnostic to the language of the application and can be applied to existing applications usually with little to no code changes.
Features of a service mesh include:
| Feature | Description |
|---|---|
| Traffic Management |
|
| Zero Trust |
|
| Separate Planes |
|
 Figure 5-4 - Service Mesh
Figure 5-4 - Service Mesh
Access Control and Policy Enforcement
Access control policies evolve as the business requirements change -- tying the access control policies to the micro-service code is a bad practice.
The following table lists the considerations when it comes to access control and policy enforcement:
| Consideration | Description |
|---|---|
| Open Policy Agent (OPA) |
|
| Policy Enforcement |
|
| API Gateway |
|
| Cloud IAM |
|
Policy enforcement systems could be integrated with API gateways to enforce the policies at the API gateway level. The following figure illustrates the sequence of events that happens when an API gateway intercepts client requests to apply authorization policies using OPA.
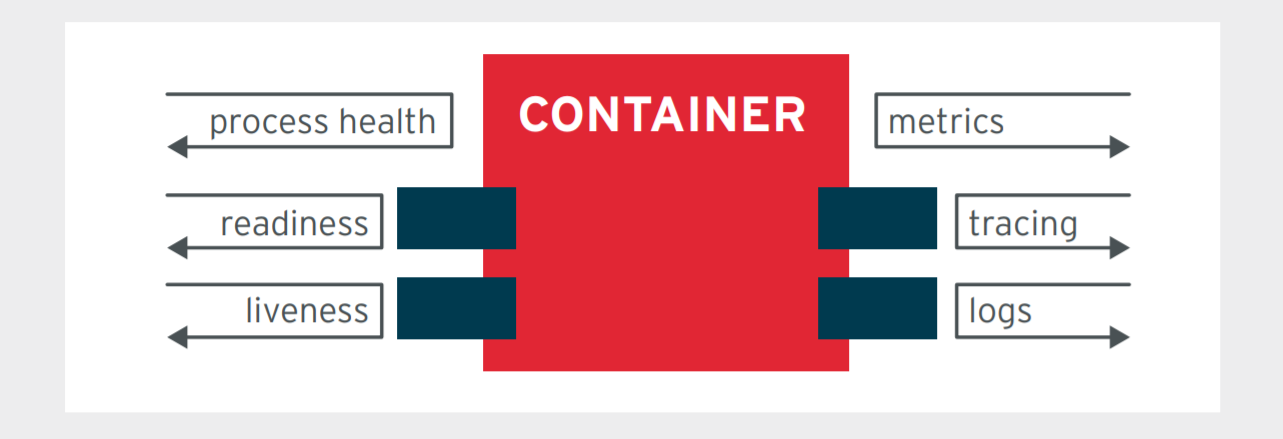 Figure 5-5 - API Gateway with OPA
Figure 5-5 - API Gateway with OPA
5.2 Securing Container Runtime
In order to run containers securely, we aim to do the following:
- Use least privilege to carry out the task at hand.
- Enforce resource allocation
- Limit communication between applications, and to and from the outside world, to a defined and deterministic set of connections.
Least-Privilege Security Settings
Least privilege is a security concept that requires that every module or program in a computer system be granted the least amount of privilege needed to fulfill its function. This helps to reduce the potential attack surface of the system.
The following table lists the considerations when it comes to least-privilege security settings in containers:
| Consideration | Description |
|---|---|
| Avoid Root | Run containers as non-root users unless specific privileges are required (e.g., modifying the host system, binding to privileged ports) |
| Read-Only Root Filesystem | Prevent attackers from writing executable files by setting the root filesystem as read-only, unless write access is essential. |
| Limit Host Volume Mounts | Restrict the ability to mount sensitive host directories into containers to prevent unintended modifications. |
| Disable Privileged Access | Set privileged and allowPrivilegeEscalation to false unless specifically required. |
| Restrict System Calls | Use seccomp profiles to limit system calls available within containers, minimizing potential attack vectors. |
Resource Usage
Containers have multiple dimensions at runtime, such as:
- memory usage,
- CPU usage, and
- other resource consumption dimensions.
The following table lists the considerations when it comes to resource usage in containers:
| Consideration | Description |
|---|---|
| Define the Required Resources | Define and enforce resource requirements (CPU, memory) for each container to ensure predictable resource allocation and prevent resource starvation. |
Network Policies
The following table lists the considerations when it comes to network policies in containers:
| Consideration | Description |
|---|---|
| "Layer 3" Network segmentation | Restrict pod-to-pod communication and external access using network policies to enhance security and implement network segmentation. |
| Set Limits | Consider network policy limitations (pod port focus, service port changes, logging capabilities, FQDN support). |
| Default Allow-All Policy | By default, Kubernetes has an allow-all policy, and does not restrict the ability for pods to communicate with each other. |
5.3 Securing Traffic
Microservices developer should focus on the business functionality of a microservice, and the management of other concerns like security, observability, and resiliency should be handled by specialized components.
The API Gateway and Service Mesh are two architectural patterns that help us achieve this goal.
North-South Traffic
North-South traffic indicates any traffic caused by the communication between the client/consumer applications and the APIs. To secure the north-south traffic, an API gateway is typically deployed at the edge of a network.
| Consideration | Description |
|---|---|
| North-South Traffic (Client-API Communication) |
|
East-West Traffic
East-West traffic indicates the inter-micro-service communications.
Securing this type of traffic has three aspects:
| Consideration | Description |
|---|---|
| East-West Traffic (Inter-Microservice Communication) |
|
Event-Driven Systems
Event-driven systems rely on data streams and the propagation of events to trigger actions. These systems are composed of event producers, event consumers, and event brokers.
The following table lists the considerations when it comes to securing event-driven systems:
| Consideration | Description |
|---|---|
| Message broker | Secure event traffic between microservices using message brokers like |
| Transport Layer Security | Use TLS/mTLS to encrypt data in transit between microservices and the message broker. |
| Control access | Use IAM to control which microservices are permitted to connect to the message broker and to authenticate the clients connecting to it. |
| Access Control Lists (ACLs) | ACLs permit or deny various micro-services performing different types of actions on the message broker resources such as topics and queues. |
5.4 Secure Coding Practices
Secure coding practices are a set of guidelines and best practices that help developers write secure code. The Government of Canada provides guidance on secure coding practices in the Secure Coding Practices Guide - on GCPedia, which are base in large part on the OWASP Top 10.
In addition to the Secure Coding Practices Guide, the following list should be considered when developing microservices:
| Consideration | Description |
|---|---|
| Crypto Libraries |
|
| Data in Transit |
|
| Protect Production Branch |
|
| Secrets Management |
|
| Input Validation |
|
| Error Handling |
|
| Logging |
|
| Dependency Management |
|
| Secure Configuration |
|
5.5 Architecting Your Application for Cloud
The purpose of this section is to outline aspects of scalable, resilient, and portable microservices to facilitate them being deployed and monitored to the Cloud.
The following principles are recommended:
| Principle | Description |
|---|---|
| Single Concern |
|
| Immutable Container Images |
|
| Self-Contained Image |
|
| Lifecycle Conformance |
|
| Process Disposability |
|
5.6 Securing Container Images
The following table provides a list of considerations when it comes to securing container images:
| Consideration | Description |
|---|---|
| Image Signing |
|
| Software Bill of Materials (SBOM) |
|
| Scan Images for Vulnerabilities |
|
| Patch Container Image |
|
| Container Image Storage |
|
The following figure illustrates the system components, activities, and artifacts involved in securing container images.
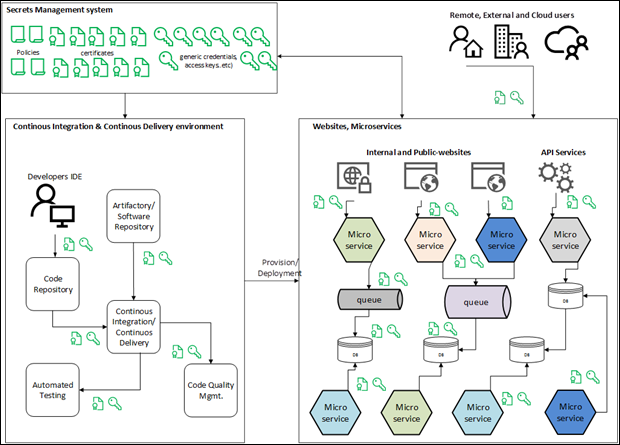 Figure 5-6 - Securing Container Images
Figure 5-6 - Securing Container Images
5.7 Observability
Observability is a measure of how well internal states of a system can be inferred from knowledge of its external outputs. In the context of microservices, observability is the ability to understand the internal state of the system by observing the outputs of its components. Observability is a key requirement for microservices, as it allows you to monitor, debug, and optimize your services.
The following table lists the considerations when it comes to observability in microservices:
| Consideration | Description |
|---|---|
| Health Check and Auto Healing |
|
| Logging |
|
| Monitoring and Custom Metrics |
|
| Tracing |
|
| Anomaly Detection |
|
5.8 Secrets Management
Secrets management is a critical component of container security. A secret, in the context of containers, is any information that will put your organization, customer or application at risk if exposed to an unauthorized person or entity. This includes API keys, ssh keys, passwords, etc.
The following table lists the considerations when it comes to secrets management in microservices:
| Consideration | Description |
|---|---|
| Secure Storage |
|
| Dynamic Secret Distribution |
|
| Access Control |
|
| Audit |
|
| Secret Rotation |
|
Secret Management Tools
Secret management solutions fall into two broad categories:
| Category | Tools |
|---|---|
| Cloud Provider Tools | |
| Open Source Tools |
5.9 Continuous Integration/Continuous Deployment (CI/CD)
Your CI/CD pipeline plays a pivotal role in securing your microservices. The following table lists the considerations when it comes to CI/CD security:
| Consideration | Description |
|---|---|
| Code Commit Signing | Sign your commits to prove that the code you submitted came from you and wasn't altered while you were transferring it. |
| Use Machine-to-Machine (M2M) Authentication | Secure access between your CI/CD pipeline and your secret manager, using M2M authentication such as OAuth 2.0. |
| Integrate Security Testing in Pipeline | Integrate security testing into your CI/CD pipeline to identify security flaws before they can be exploited. |
| Code analysis and scanning | Use static code analysis, dynamic analysis, and third-party dependency scanning to identify vulnerabilities. |
5.10 Infrastructure as Code (IaC)
Infrastructure as Code (IaC) is the process of managing and provisioning compute infrastructure through machine-readable definition files rather than physically configuring the hardware or by using interactive configuration tools.
The following table lists the considerations when it comes to IaC security:
| Consideration | Description |
|---|---|
| Use IaC Tools |
|
| Secure IaC Configuration |
|
| Automate Security Compliance |
|
Page details
- Date modified: